From the WordPress Admin Menu, click Post Saint > Bulk Import Posts
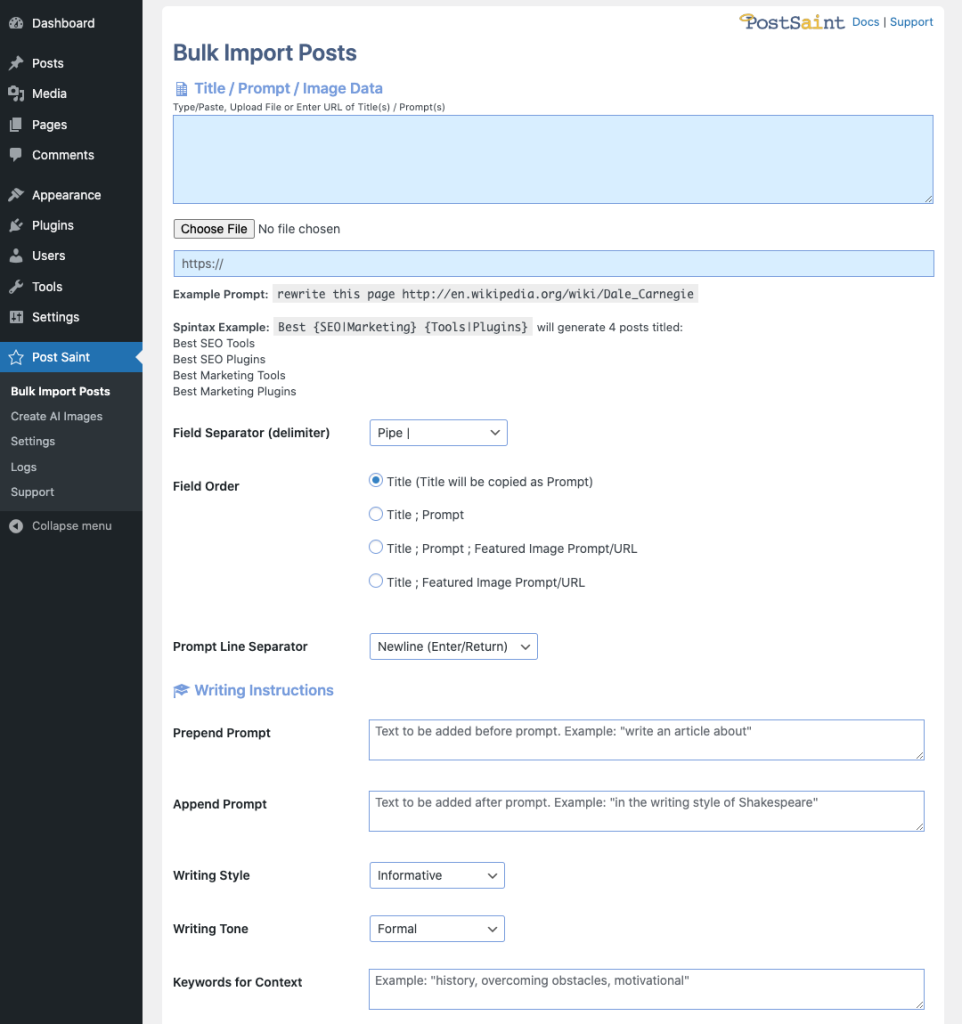
Bulk Post Data #
You can input your Bulk Post Data in one of three ways:
- Paste your data in the text area field
- Upload your data file form your computer
- Specify a URL
Select the appropriate Field Separator (delimiter), Field Order, and Line Separator for your data entered above.
Spintax #
You can use Spintax in your Title fields. Wrap your spintax in curly braces, with values separated by a pipe character
Spintax example: {Miami|Las Vegas|New York}
Note: When using spintax, you must not use the pipe (|) character as the field separator, semicolon (;) is recommended.
Writing Instructions #
Prepend & Append Prompt #
Under Writing Instructions, you can specify text to Prepend Prompt which will be added before the prompt. The Append Prompt field will add text after the prompt.
Writing Style #
For the Writing Style field, you can select a style such as Informative, Descriptive, Creative, etc..

Writing Tone #
The Writing Tone field has options such as Formal, Neutral, Assertive, Sarcastic, Skeptical, etc..

Keywords can be specified to give “hints” for the type of content you want written.
OpenAI Parameters #
Under the OpenAI Parameters, you can adjust the setting to your liking. Below are the definitions for each field:
Model #
While Davinci is generally the most capable, the other models can perform certain tasks extremely well with significant speed or cost advantages. For example, Curie can perform many of the same tasks as Davinci, but faster and for 1/10th the cost.
We recommend using Davinci while experimenting since it will yield the best results. Once you’ve got things working, we encourage trying the other models to see if you can get the same results with lower latency. You may also be able to improve the other models’ performance by fine-tuning them on a specific task.
Davinci #
Davinci is the most capable model family and can perform any task the other models can perform and often with less instruction. For applications requiring a lot of understanding of the content, like summarization for a specific audience and creative content generation, Davinci is going to produce the best results. These increased capabilities require more compute resources, so Davinci costs more per API call and is not as fast as the other models.
Another area where Davinci shines is in understanding the intent of text. Davinci is quite good at solving many kinds of logic problems and explaining the motives of characters. Davinci has been able to solve some of the most challenging AI problems involving cause and effect.
Good at: Complex intent, cause and effect, summarization for audience
Curie #
Curie is extremely powerful, yet very fast. While Davinci is stronger when it comes to analyzing complicated text, Curie is quite capable for many nuanced tasks like sentiment classification and summarization. Curie is also quite good at answering questions and performing Q&A and as a general service chatbot.
Good at: Language translation, complex classification, text sentiment, summarization
Babbage #
Babbage can perform straightforward tasks like simple classification. It’s also quite capable when it comes to Semantic Search ranking how well documents match up with search queries.
Good at: Moderate classification, semantic search classification
Ada #
Ada is usually the fastest model and can perform tasks like parsing text, address correction and certain kinds of classification tasks that don’t require too much nuance. Ada’s performance can often be improved by providing more context.
Good at: Parsing text, simple classification, address correction, keywords
Note: Any task performed by a faster model like Ada can be performed by a more powerful model like Curie or Davinci.
Finding the right model #
Experimenting with Davinci is a great way to find out what the API is capable of doing. After you have an idea of what you want to accomplish, you can stay with Davinci if you’re not concerned about cost and speed or move onto Curie or another model and try to optimize around its capabilities.
Max Tokens #
The maximum number of tokens to generate in the completion.
The token count of your prompt plus max_tokens cannot exceed the model’s context length. Most models have a context length of 2048 tokens (except for the newest models, which support 4096).
A helpful rule of thumb is that one token generally corresponds to ~4 characters of text for common English text. This translates to roughly ¾ of a word (so 100 tokens ~= 75 words).
Temperature #
Higher values means the model will take more risks. Try 0.9 for more creative applications, and 0 (argmax sampling) for ones with a well-defined answer.
We generally recommend altering this or top_p but not both.
Top P #
An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.
We generally recommend altering this or temperature but not both.
Frequency Penalty #
Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model’s likelihood to repeat the same line verbatim.
Presence Penalty #
Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model’s likelihood to talk about new topics.
Image #
If image prompt data is included for intention of creating a Featured Image for generated posts, set the options (defined below) for the image creation. Instead of specifying image prompts, you may alternatively specify an Image URL from which to create the Featured Image of generated posts.
Image Style #
For the Image Style field, you can select an image rendering texture such as 3D, Abstract, Cartoon, Cyberpunk, Fantasy, Futurism, Noir, Pencil Sketch, Watercolor, etc..
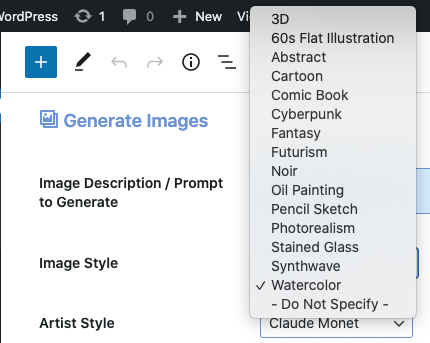
Artist Style #
For the Artist Style field, you can select a famous artist’s name such as Salvador Dali, Claude Monet, Pablo Picasso, Rembrandt, Vincent van Gogh, Andy Warhol, etc..
Number of Images to Generate #
Simply enter the number of images to generate on a scale of 1-10. More images will take longer to generate and return results.
Image Size #
Currently, DALL-E offers (3) 1:1 aspect ratio (square) image sizes to generate images: 256×256, 512×512, 1024×1024
Media Library Fields to Insert Image Prompt #
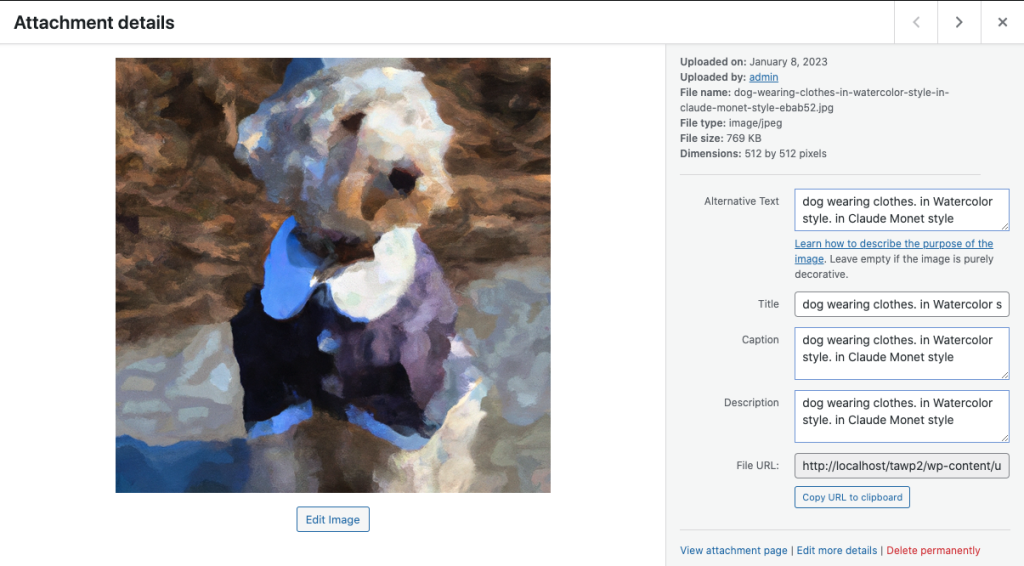
This field allows you to insert the complete image prompt used to generate the image(s) into the Caption and Description fields for the image in the Media Library in addition to the Alternative Text and Title fields.